Főoldal> Blog> Analitika Blog

Csentes Zoltán, SEO szakértő
Az elmúlt 20 évben az online marketing minden területén megfordultam, minden hárombetűs területet kipróbáltam, végül a keresőoptimalizálás és webanalitika szakértője lettem.
Az XPath hasonlóan a korábban bemutatott eszközökhöz, szintén egy elég érdekes területe az AdOpsnak. Viszont ez a programnyelv nem csak ott, hanem a SEO területén is igen hasznos funkciókat nyújthat. Ebben a posztban megismerkedünk az XPath működésével, és konkrét példákon keresztül bemutatom mire is tudja használni egy SEO szakértő, vagy AdOps szakember.
Mi az XPath?
Az XPath egy viszonylag egyszerű, úgynevezett lekérdező programnyelv, amit a webben történő "turkálásra" terveztek. Segítségével egy adott XML vagy HTML forrásból a nekünk kellő elemeket, értékeket tudjuk kinyerni. Hasonlóan működik, mint a CSS Selector, csak ez többet tud. Az XPath segítségével nem csak az oldal struktúráján tudunk végigmenni, hanem az oldalon található szövegeken is.
Mire használható az XPath?
A teljesség igyénye nélkül lássunk néhány példát, amire SEO-ban használni tudjuk ezt a programnyelvet:
- feltérképezhetjük egy weboldal sitemapjét és kigyűjthetjük csak a linkeket
- végigmehetünk egy webáruház összes termékén és listázhatjuk az összes terméket árral
- kigyűjthetjük megadott weboldalak meta tagjeit
- kigyűjthetjük google keresőből a kulcsszóra éppen aktuális top találatokat
- kigyűjthetjük az email címeket egy weboldalról
Hogyan működik az XPath
Amikor az XPath ránéz egy weboldal forráskódjára, akkor egy fa szerkezetet lát. A fa gyökere a <HTML>, majd jön a <HEAD>, <BODY>, és azon belül pedig a <DIV>, <H1-2-3...h2> és a <p> elemek. Az elemeken belül pedig jön a tartalom.
Ha tehát egy adott oldal címét szeretnénk kinyerni, akkor ezt az XPath parancsot kell használnunk:
/html/head/titleDe ugyanezt érhetjük el ha azt mondjuk, hogy listázzon minden olyan elemet ahol az elem neve "title", mivel az oldalban úgyis csak egy ilyen elemünk van:
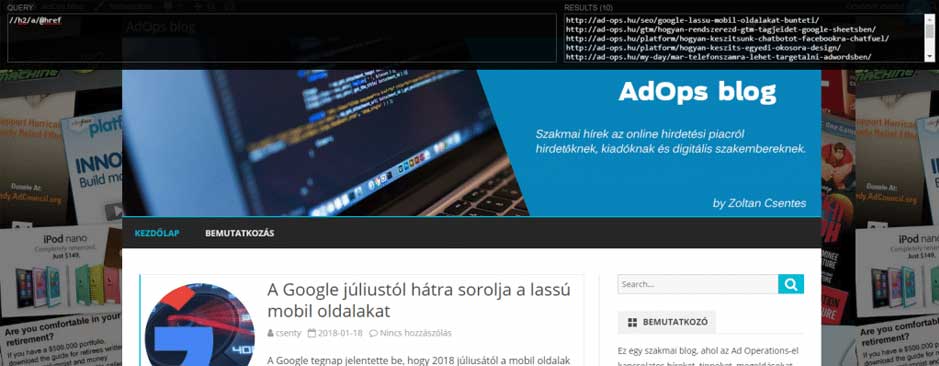
//titleMost bonyolítsuk egy kicsit. Tegyük fel, hogy a MOZ.com/blog oldalból szeretnénk listázni az első oldalon lévő posztok címeit:
//h2/aHa pedig csak az URL-ekre vagyunk kíváncsiak, akkor ezt a parancsot kell használnunk:
//h2/a/@hrefMost, hogy látod milyen egyszerű az XPath használata, ismerkedjünk meg kicsit jobban az XPath eszközökkel, hogy ki is tudd próbálni.
XPath eszközök
Az interneten rengeteg online tool érhető el, ami ezt a programnyelvet használja: XPath tester, XPath online editor, XPath scraper, finder és még sok más. Ezek közül amit én nagyon sokszor használok az XPath scraper böngésző bővítmény.
Telepítsük fel a következő bővítményeket Chromeba. Mindkét kiegészítő hasznos a számunkra. Az XPath Helper egy layert tesz az oldalra amiben szabadon tesztelhetjük az XPath parancsunkat az adott oldalon.
xpath helper teszt
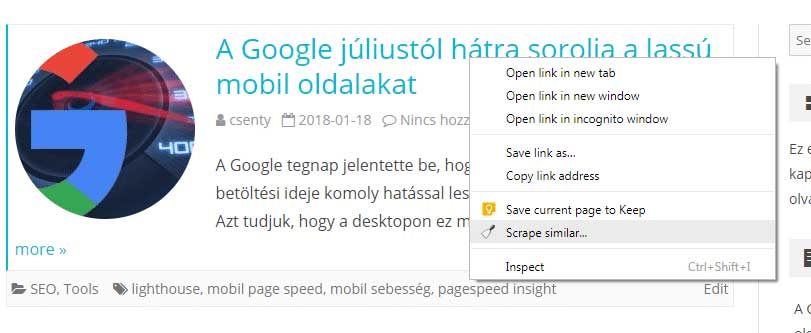
A Scraperrel pedig ha az oldal bármelyik elemén (mondjuk a posztokon) jobb klikket nyomunk, akkor megjelenik a "Scrape similar..." menüpont, amivel kigyűjthetjük az oldalról a hasonló elemeket.
xpath scraper 1
Ha például a blog posztjaira és azok linkjére vagyok kíváncsi akkor így:

xpath scraper 2
A teszteléshez az egyik legjobb eszköz a Google Developer Tools, amit az F12-vel tudsz előhívni. Ezzel a kódsorral például a legfrissebb poszt neveket gyűjtöttem ki:
See the Pen MOZ top10 blog title by Csentes Zoltán (@csenty) on CodePen.
Az eredmény pedig a console-ban így néz ki:

xpath google dev-tool
Egy érdekesség még a consol-hoz: ha az XPath kódot ebben a formában írod be a consolba, akkor könnyedén végre tudsz hajtani bármilyen parancsot:
$x("/html/head/ title/text()") Most, hogy megismerkedtünk az alapvető dolgokkal, nézzünk néhány érdekes példát.
Google Top 10 találat listázása
Tegyük fel, hogy szeretnénk kilistázni a Google SERP első oldalán megjelenő találatokat egy adott kulcsszóra. Keressünk rá a kulcsszóra, F12 és a Console-ba írjuk be ezt:
See the Pen Google Top 10 results by Csentes Zoltán (@csenty) on CodePen.
XPath használata Google Spreadsheetben
A feladat egy olyan Google táblázat készítése, ami a versenytársaink blogjából listázza a legújabb posztokat. A táblázatot és a benne lévő képleteket itt tudod megnézni: XPath táblázatban.
Ha csak az eredményre vagy kíváncsi íme:

ImportXML használata google spreadsheet-ben
Mi is történt itt. A spreadsheetnek van egy ImportXML függvénye, amivel komplett XML-eket tudunk behúzni. Esetünkben itt annyit módosítottunk, hogy nem XML fájlt adtunk meg, hanem a céloldalt, továbbá XPath segítségével megadtuk, hogy mely elemeket listázza.
Listázzuk ki a lap.hu keresőmarketing dobozának tartalmát
Ehhez a legegyszerűbb, ha használjuk a Scraper bővítményt. Keressük meg a dobozt és jobb klikkel válasszuk ki az első elemet. Rögtön meg is kapjuk, hogy mi az XPath parancs, ami ezeket kilistázza:
//div[3]/div[9] /div/aMost indítsuk el az XPath Helper kiegészítőt és írjuk be ezt a query részbe. És voilá! A results részben a lista a megjelenő cégekről. Ha linket is szeretnénk látni, akkor az XPath részt így módosítsuk:
//div[3]/div[9]/ div/a/@hrefAz XPath használatával nem csak a napi SEO munkánkat tudjuk megtámogatni, hanem mint láthattuk a konkurencia figyelésben is hasznos lehet. Amikor az Edigitalnál dolgoztam, volt egy kimondottan a versenytársak árait figyelő scriptünk, ami ugyanezen az elven működött. Részben ennek is köszönhette a cég, hogy az árakkal mindig sikerült a versenytársak alá menni, és mára az ország legnagyobb webshopja lett.
Hasznos Xpath parancsok
Végül összegyűjtöttem a legfontosabb Xpath parancsokat, amiket a leggyakrabban használunk:
//*[@class='classname'] - Azokat az elemeket listázza, amik a classname class-t használják //*[@class='r']/a/@href - Azokat a linkeket listázza, amik 'r' classban vannak //comment() - csak a kommenteket listázza //text() - csak a szöveges tartalmat listázza //* - minden elemet listáz kivéve a comment és text elemeket //p/text() - minden p elemen belüli szöveget listáz //li[position() = 1] - csak az első li elemet listázza //li[last()] - csak az utolsó li elemet listázza //li[position()%2=0] - csak a páros li elemeket listázza //li[a or h2] - azokat a li elemeket listázza amik tartalmaznak vagy a-t vagy h2-t //li[ a [ text() = "link" ] ] - li elemeket listáz amik a elemet tartalmaznak aminek a szövege "link" //a | //h2 - listázza mindkét elemet //a/@href - az összes link url-t listázza //a[starts-with(@href, "https")] - csak a https linkeket adja vissza